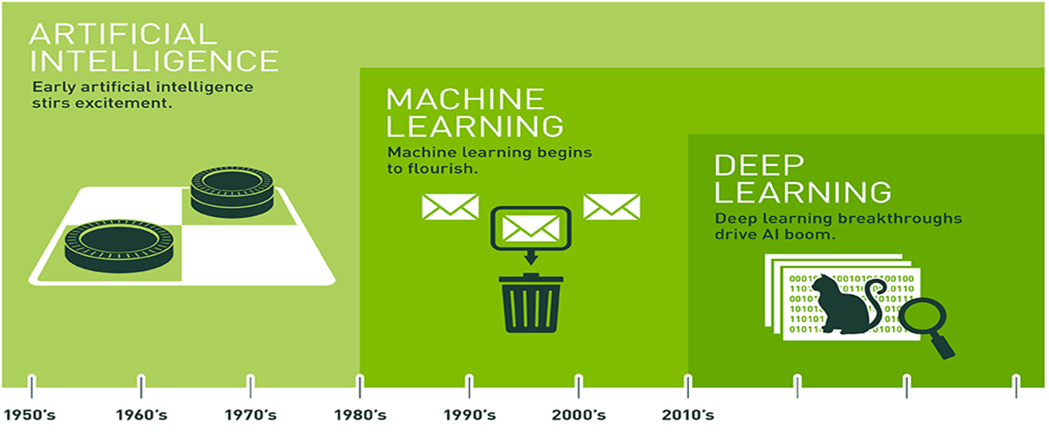
AI and Deep Learning Evolution
- As humans, we generalize what we see based on our experience. In a similar way, we can use a branch of AI called Machine Learning to generalize and classify images based on experience in the form of lots of example data.
- In particular, we will use deep neural network models, or Deep Learning to recognize relevant patterns in an image dataset, and ultimately match new images to correct answers.
Deep Learning Models
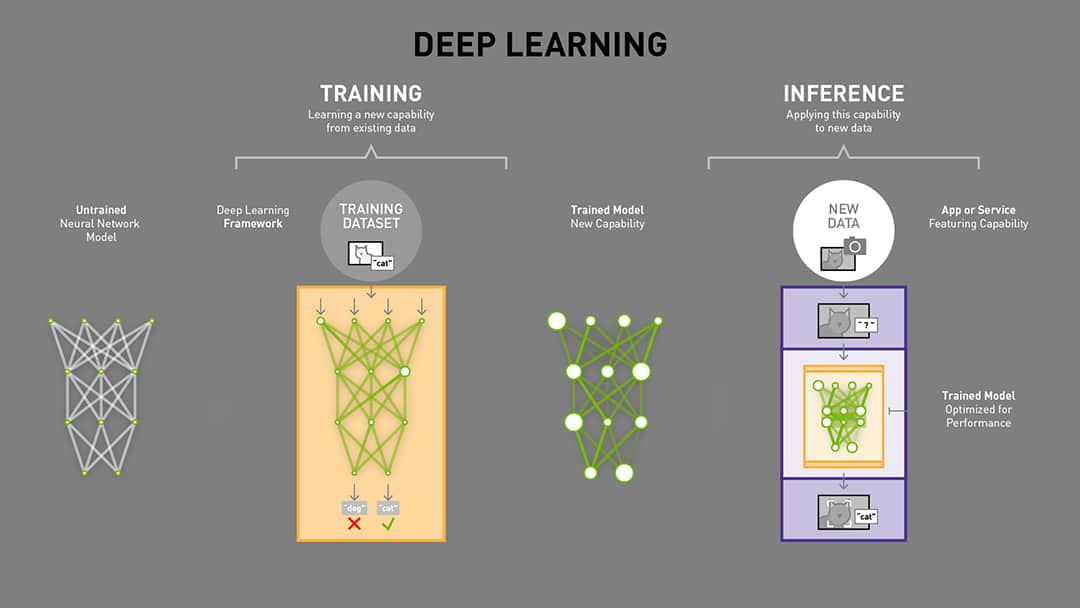
- A Deep Learning model consists of a neural network with internal parameters, or weights, configured to map inputs to outputs. In Image Classification, the inputs are the pixels from a camera image and the outputs are the possible categories, or classes that the model is trained to recognize. The choices might be 1000 different objects, or only two. Multiple labeled examples must be provided to the model over and over to train it to recognize the images. Once the model is trained, it can be run on live data and provide results in real time. This is called inference.
- Before training, the model cannot accurately determine the correct class from an image input, because the weights are wrong.
- Labeled examples of images are iteratively submitted to the network with a learning algorithm. If the network gets the “wrong” answer (the label doesn’t match), the learning algorithm adjusts the weights a little bit. Each iteration of training is supposed to improve the model’s performance, it is termed as epoch.
- Over many computationally intensive iterations, the accuracy improves to the point that the model can reliably determine the class for an input image.
Convolutional Neural Networks (CNNs) Overview
- Deep learning relies on Convolutional Neural Network (CNN) models to transform images into predicted classifications. A CNN is a class of artificial neural network that uses convolutional layers to filter inputs for useful information, and is the preferred network for image applications.
- An artificial neural network is a computational model. At each layer, the network transforms input data by applying a nonlinear function to a weighted sum of the inputs. The intermediate outputs of one layer, called features, are used as the input into the next layer. The neural network, through repeated transformations, learns multiple layers of nonlinear features (like edges and shapes), which it then combines in a final layer to create a prediction (of more complex objects).
- The convolution operation specific to CNNs combines the input data (feature map) from one layer with a convolution kernel (filter) to form a transformed feature map for the next layer.
- CNNs for image classification are generally composed of an input layer (the image), a series of hidden layers for feature extraction (the convolutions), and a fully connected output layer (the classification).
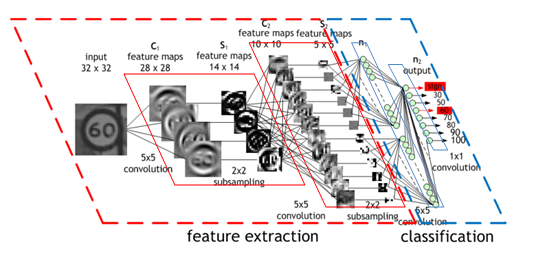
- As it is trained, the CNN adjusts automatically to find the most relevant features based on its classification requirements.
- For example, a CNN would filter information about the shape of an object when confronted with a general object recognition task but would extract the color of the bird when faced with a bird recognition task. This is based on the CNN’s recognition through training that different classes of objects have different shapes but that different types of birds are more likely to differ in color than in shape.
Transfer Learning:
- The Transfer Learning a deep learning technique enables developers to harness a neural network used for one task and apply it to another domain.
- For Example, take image recognition. Let’s say that you want to identify horses, but there aren’t any publicly available algorithms that do an adequate job. With transfer learning, you begin with an existing convolutional neural network commonly used for image recognition of other animals, and you tweak it to train with horses.
- Developers might start with ResNet-50 — a pre-trained deep learning model consisting of 50 layers — because it has a high accuracy level for identifying cats or dogs. Within the neural network are layers that are used to identify outlines, curves, lines and other identifying features of these animals. The layers required a lot of labeled training data, so using them saves a lot of time. Those layers can be applied to the task of carrying out the same identification on some horse features. You might be able to identify eyes, ears, legs and outlines of horses with ResNet-50, but to determine it was a horse and not a dog might require some additional training data. And with additional training by feeding labeled training data for horses — more horse-specific features can be built into the model.
- How it works:
- First, you delete what’s known as the “loss output” layer, which is the final layer used to make predictions, and replace it with a new loss output layer for horse prediction. This loss output layer is a fine-tuning node for determining how training penalizes deviations from the labeled data and the predicted output.
- Next, you would take your smaller dataset for horses and train it on the entire 50-layer neural network or the last few layers or just the loss layer alone. By applying these transfer learning techniques, your output on the new CNN will be horse identification.
- Transfer learning isn’t just for image recognition. Recurrent neural networks, often used in speech recognition, can take advantage of transfer learning, as well. However, you’ll need two similar speech-related datasets, such as a million hours of speech from a pre-existing model and 10 hours of speech specific to the new task.
- Baidu’s Deep Speech neural network offers a jump start for speech-to-text models, for example, allowing an opportunity to use transfer learning to bake in special speech features.
- Why & When to use Transfer Learning:
- Transfer learning is useful when you have insufficient data for a new domain you want handled by a neural network and there is a big pre-existing data pool that can be transferred to your problem.
- So you might have only 1,000 images of horses, but by tapping into an existing CNN such as ResNet, trained with more than 1 million images, you can gain a lot of low-level and mid-level feature definitions.
- NVIDIA TAO Toolkit:
- For developers and data scientists interested in accelerating their AI training workflow with transfer learning capabilities, the NVIDIA TAO Toolkit offers GPU-accelerated pre-trained models and functions to fine-tune your model for various domains such as intelligent video analytics and medical imaging.
ResNet (Residual Networks)
- There are a number of world-class CNN architectures available to application developers for image classification and image regression.
- PyTorch and other frameworks include access to pretrained models from past winners of the famous Imagenet Large Scale Visual Recognition Challenge (ILSVRC), where researchers compete to correctly classify and detect objects and scenes with computer vision algorithms.
- In 2015, ResNet swept the awards in image classification, detection, and localization.
- ResNet is a residual network, made with building blocks that incorporate “shortcut connections” that skip one or more layers.
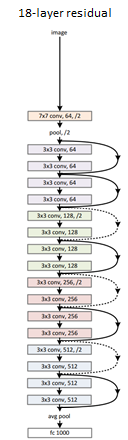
- The shortcut output is added to the outputs of the skipped layers. The authors of Deep Residual Learning for Image Recognition demonstrate that this technique makes the network easier to optimize, and have higher accuracy gains at greatly increased depths.
- The ResNet architectures presented range from 18-layers deep, all the way to 152-layers deep! The smallest network, ResNet-18 provides a good balance of performance and efficiency sized well for the Jetson Nano.
- PyTorch includes a pre-trained ResNet-18 model that was trained on the ImageNet 2012 classification dataset, which consists of 1000 classes. In other words, the model can recognize 1000 different objects already! Within the trained neural network are layers that find outlines, curves, lines, and other identifying features of an image. Important image features that were already learned in the original training of the model are now re-usable for our own classification task.
- The last layer for ResNet-18 is a fully connected (fc) layer, pooled and flattened to 512 inputs, each connected to the 1000 possible output classes.
Classification Vs. Regression:
- Unlike Image Classification applications, which map image inputs to discrete outputs (classes), the Image Regression task maps the image input pixels to continuous outputs.
- Continuous outputs can be the X and Y coordinates of various features on a face, such as a nose. Mapping an image stream to a location for tracking can be used in other applications, such as following a line in mobile robotics.
- Tracking isn’t the only thing a Regression model can do though. The output values could be something quite different such as steering values, or camera movement parameters.
- Evaluation:
- Classification and Regression also differ in the way they are evaluated.
- The discrete values of classification can be evaluated based on accuracy, i.e. a calculation of the percentage of “right” answers.
- In the case of regression, we are interested in getting as close as possible to a correct answer. Therefore, the root mean squared error can be used.
Further References:
- Artificial Neural Network
- Explains: Neural Networks terms like: Neurons/Nodes, Unit, Activation Function, Layers
- NVIDIA cuDNN
- The NVIDIA CUDA® Deep Neural Network library (cuDNN) is a GPU-accelerated library of primitives for deep neural networks. cuDNN provides highly tuned implementations for standard routines such as forward and backward convolution, pooling, normalization, and activation layers.
- cuDNN accelerates widely used deep learning frameworks, including Caffe2, Chainer, Keras, MATLAB, MxNet, PaddlePaddle, PyTorch, and TensorFlow.
- NVIDIA TensorRT
- TensorRT-based applications perform up to 40X faster than CPU-only platforms during inference. With TensorRT, you can optimize neural network models trained in all major frameworks, calibrate for lower precision with high accuracy.
- TensorRT is built on CUDA®, NVIDIA’s parallel programming model, and enables you to optimize inference leveraging libraries.
- TensorRT provides optimizations for production deployments of deep learning inference applications such as video streaming, speech recognition, recommendation, fraud detection, text generation, and natural language processing.
- TensorRT internally use cuDNN for inference but with some extension.
- cuDNN is a operation level API and user will need to convert the model layer by layer.
- TensorRT provide several parsers and can support most public dnn model format directly.
- Amazon SageMaker Neo makes it easier to get faster inference for more ML models with NVIDIA TensorRT
- NVIDIA TAO TOOLKIT
- Creating an AI/machine learning model from scratch can cost you a lot of time and money. Transfer learning is a popular technique that can be used to extract learned features from an existing neural network model to a new one.