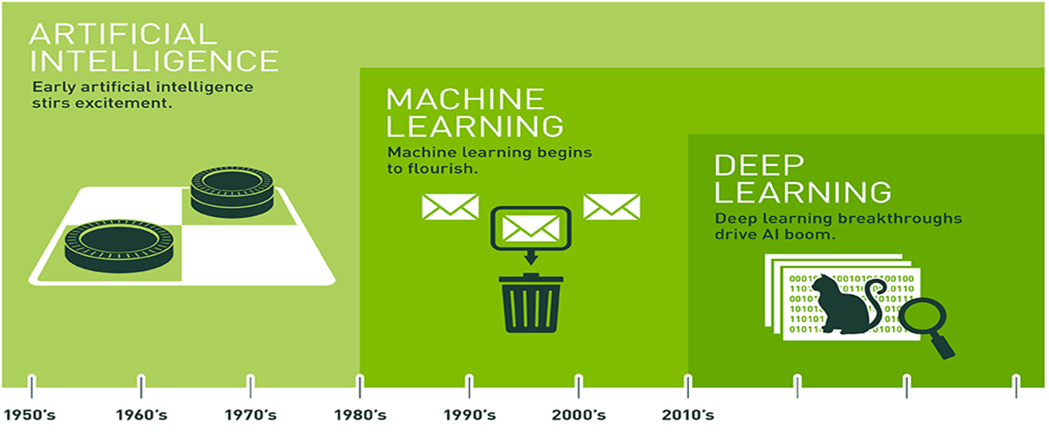
AI and Deep Learning Evolution
- As humans, we generalize what we see based on our experience. In a similar way, we can use a branch of AI called Machine Learning to generalize and classify images based on experience in the form of lots of example data.
- In particular, we will use deep neural network models, or Deep Learning to recognize relevant patterns in an image dataset, and ultimately match new images to correct answers.
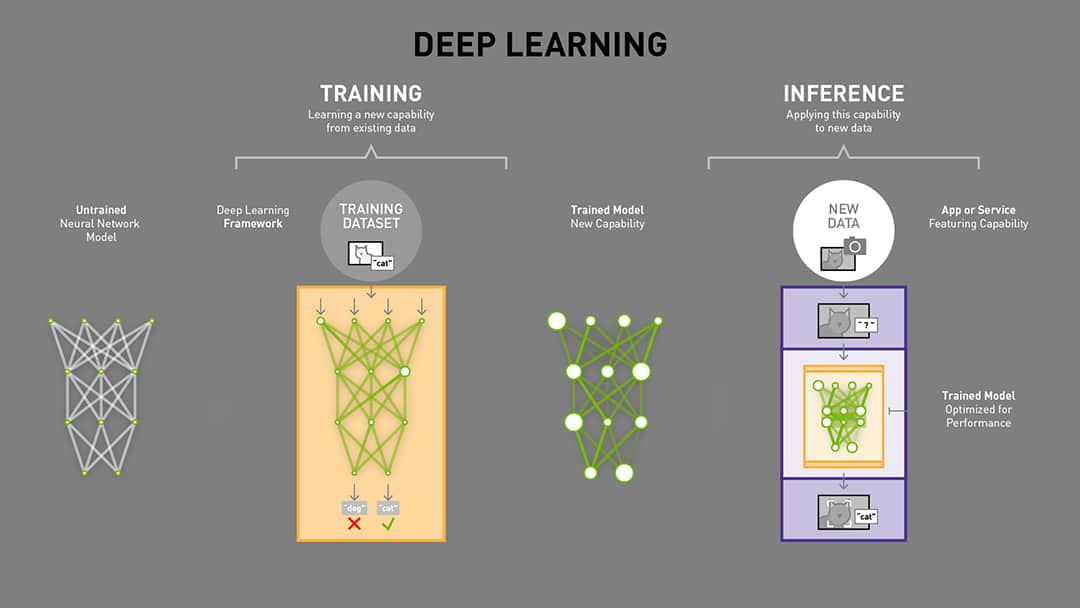
Deep Learning Models
- A Deep Learning model consists of a neural network with internal parameters, or weights, configured to map inputs to outputs. In Image Classification, the inputs are the pixels from a camera image and the outputs are the possible categories, or classes that the model is trained to recognize. The choices might be 1000 different objects, or only two. Multiple labeled examples must be provided to the model over and over to train it to recognize the images. Once the model is trained, it can be run on live data and provide results in real time. This is called inference.
- Before training, the model cannot accurately determine the correct class from an image input, because the weights are wrong.
- Labeled examples of images are iteratively submitted to the network with a learning algorithm. If the network gets the “wrong” answer (the label doesn’t match), the learning algorithm adjusts the weights a little bit. Each iteration of training is supposed to improve the model’s performance, it is termed as epoch.
- Over many computationally intensive iterations, the accuracy improves to the point that the model can reliably determine the class for an input image.
Neural Networks:
- Deep Learning is all about Neural Networks.
- The structure of a neural network is an interconnected web of Nodes/Neurons, and the Edges that join them together.
- A neural network’s main function is to receive a set of inputs, perform progressively complex calculations, and then use the output to solve a problem. Neural networks are used for lots of different applications, like Classification.
- Classification is the process of categorizing a group of objects, while only using some basic data features that describe them.
- There are lots of classifiers available today - like Logistic Regression, Support Vector Machines, Naive Bayes, and of course, neural networks.
- The activation of a classifier, produces a score. For example, say you needed to predict if a patient is sick or healthy, and all you have are their height, weight, and body temperature. The classifier would receive this data about the patient, process it, and fire out a confidence score. A high score would mean a high confidence that the patient is sick, and a low score would suggest that they are healthy.
- Neural nets are used for classification tasks where an object can fall into one of at least two different categories.
- A neural network is highly structured and comes in layers.
- The first layer is the input layer
- The final layer is the output layer
- and all layers in between are referred to as hidden layers.
- A neural net can be viewed as the result of spinning classifiers together in a layered web. This is because each node in the hidden and output layers has its own classifier.
- The results of the classification are determined by the scores at each node.
- The first neural nets were born out of the need to address the inaccuracy of an early classifier, the perceptron. It was shown that by using a layered web of perceptrons, the accuracy of predictions could be improved. As a result, this new breed of neural nets was called a Multi-Layer Perceptron[MLP].
- Forward Propagation:
- This series of events starting from the input where each activation is sent to the next layer, and then the next, all the way to the output, is known as forward propagation, or forward prop.
- Forward prop is a neural net’s way of classifying a set of inputs.
- Weights & Biases:
- Each node has the same classifier, and none of them fire randomly; if you repeat an input, you get the same output.
- Even if every node in the hidden layer received the same input, each set of inputs is modified by unique weights and biases.
- For example, the first input is modified by a weight of 10, the second by 5, the third by 6 and then a bias of 9 is added on top.
- Each edge has a unique weight, Each node has a unique bias. This means that the combination used for each activation is also unique, which explains why the nodes fire differently.
- Training Neural Networks:
- The prediction accuracy of a neural net depends on its weights and biases. We want that accuracy to be high, meaning we want the neural net to predict a value that is as close to the actual output as possible, every single time.
- The process of improving a neural net’s accuracy is called training, just like with other machine learning methods.
- To train the net, the output from forward prop is compared to the output that is known to be correct, and the cost is the difference of the two. The point of training is to make that cost as small as possible, across millions of training examples. To do this, the net tweaks the weights and biases step by step until the prediction closely matches the correct output.
- Once trained well, a neural net has the potential to make accurate predictions each time.