- Apache Flink is a framework and distributed processing engine for stateful computations over unbounded and bounded data streams.
- Flink has been designed to run in all common cluster environments, perform computations at in-memory speed and at any scale.
- Flink easily maintains application state. Its asynchronous and incremental checkpointing algorithm ensures minimal impact on processing latencies.
- Flink guarantees exactly-once state consistency in case of failures by periodically and asynchronously checkpointing the local state to durable storage.
- Flink always maintains the task state in memory or, if the state size exceeds the available memory, in access-efficient on-disk data structures, in RocksDB, an efficient embedded on-disk data store.
Flink Integration and Deployment
- Flink integrates with all common cluster resource managers such as Hadoop YARN, Apache Mesos, and Kubernetes but can also be setup to run as a stand-alone cluster.
- Flink automatically identifies the required resources based on the application’s configured parallelism and requests them from the resource manager. In case of a failure, Flink replaces the failed container by requesting new resources.
- All communication to submit or control an application happens via REST calls. This eases the integration of Flink in many environments.
Flink Features useful for Stream Processing Applications
Stream Types:
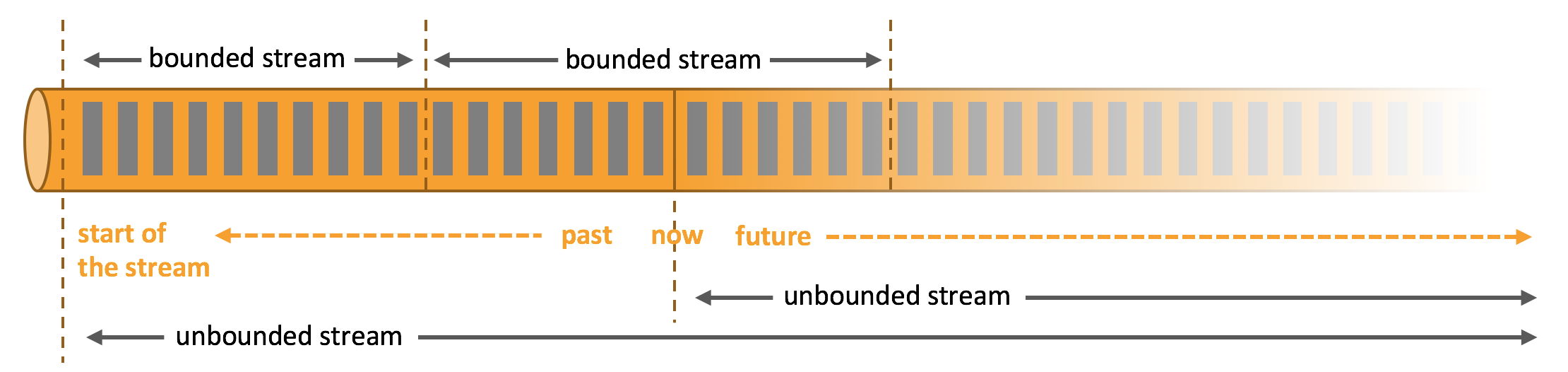
- Unbounded streams
- Unbounded streams have a start but no defined end. They do not terminate, but keep providing data as it is generated.
- Unbounded streams must be continuously processed, i.e., events must be promptly handled after they have been ingested. It is not possible to wait for all input data to arrive because the input is unbounded and will not be complete at any point in time.
- Processing unbounded data often requires that events are ingested in a specific order, such as the order in which events occurred, to be able to reason about result completeness.
- Bounded streams
- Bounded streams have a defined start and end.
- Bounded streams can be processed by ingesting all data before performing any computations.
- Ordered ingestion is not required to process bounded streams because a bounded data set can always be sorted.
- Processing of bounded streams is also known as batch processing.
Application State:
- Multiple State Primitives: Flink provides state primitives for different data structures, such as atomic values, lists, or maps. Developers can choose the state primitive that is most efficient based on the access pattern of the function.
- Pluggable State Backends: Application state is managed in and checkpointed by a pluggable state backend. Flink features different state backends that store state in memory or in RocksDB, an efficient embedded on-disk data store. Custom state backends can be plugged in as well.
- Exactly-once state consistency: Flink’s checkpointing and recovery algorithms guarantee the consistency of application state in case of a failure. Hence, failures are transparently handled and do not affect the correctness of an application.
- Very Large State: Flink is able to maintain application state of several terabytes in size due to its asynchronous and incremental checkpoint algorithm.
- Scalable Applications: Flink supports scaling of stateful applications by redistributing the state to more or fewer workers.
Time Sensitivity:
- Event-time Mode: Applications that process streams with event-time semantics compute results based on timestamps of the events. Thereby, event-time processing allows for accurate and consistent results regardless whether recorded or real-time events are processed.
- Watermark Support: Flink employs watermarks to reason about time in event-time applications. Watermarks are also a flexible mechanism to trade-off the latency and completeness of results.
- Late Data Handling: When processing streams in event-time mode with watermarks, it can happen that a computation has been completed before all associated events have arrived. Such events are called late events. Flink features multiple options to handle late events, such as rerouting them via side outputs and updating previously completed results.
- Processing-time Mode: In addition to its event-time mode, Flink also supports processing-time semantics which performs computations as triggered by the wall-clock time of the processing machine. The processing-time mode can be suitable for certain applications with strict low-latency requirements that can tolerate approximate results.
- Windowing: A useful mechanism to deal with out-of-order data is windowing—a concept that can be thought of as grouping elements of an infinite stream of data into finite sets for further (and easier) processing, based on dimensions like event time.
- Further Reference: Introducing Stream Windows in Apache Flink
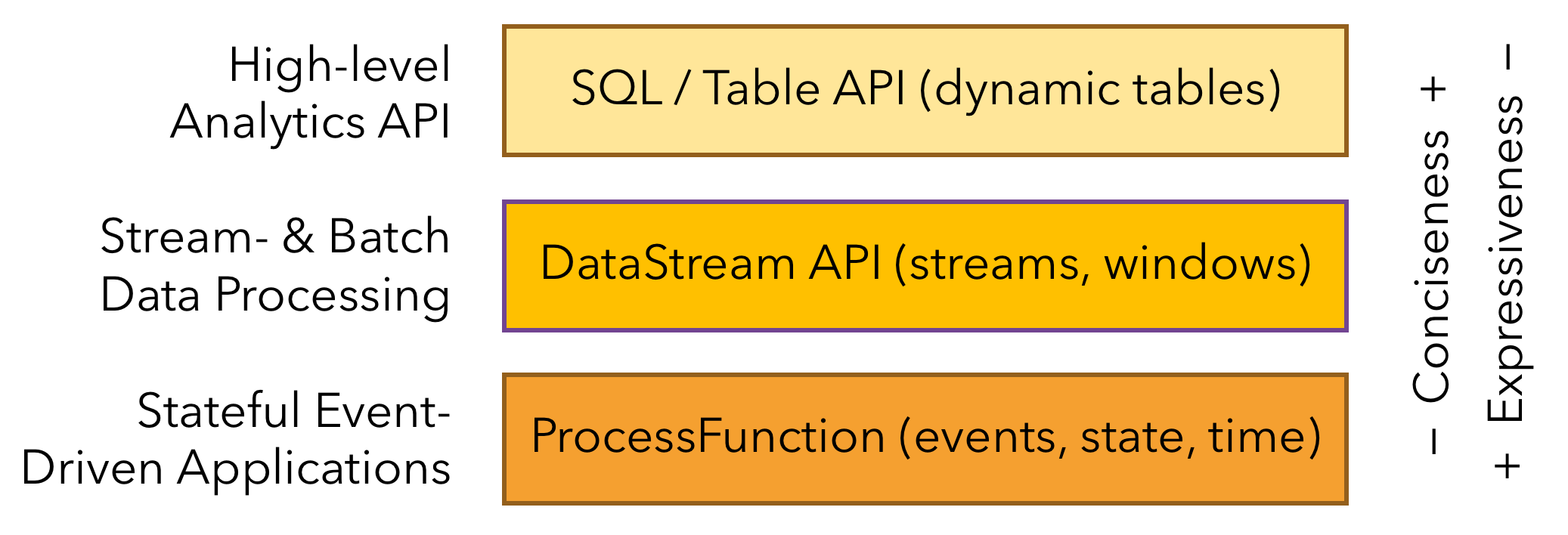
Layered APIs:
- Flink provides three layered APIs. Each API offers a different trade-off between conciseness and expressiveness and targets different use cases.
Libraries:
- Flink features several libraries for common data processing use cases. The libraries are typically embedded in an API and not fully self-contained. Hence, they can benefit from all features of the API and be integrated with other libraries.
- Complex Event Processing (CEP):
- Pattern detection is a very common use case for event stream processing. Flink’s CEP library provides an API to specify patterns of events (think of regular expressions or state machines).
- The CEP library is integrated with Flink’s DataStream API, such that patterns are evaluated on DataStreams.
- Applications for the CEP library include network intrusion detection, business process monitoring, and fraud detection.
- DataSet API:
- The DataSet API is Flink’s core API for batch processing applications.
- The primitives of the DataSet API include map, reduce, (outer) join, co-group, and iterate.
- All operations are backed by algorithms and data structures that operate on serialized data in memory and spill to disk if the data size exceed the memory budget.
- The data processing algorithms of Flink’s DataSet API are inspired by traditional database operators, such as hybrid hash-join or external merge-sort.
- Gelly:
- Gelly is a library for scalable graph processing and analysis.
- Gelly is implemented on top of and integrated with the DataSet API. Hence, it benefits from its scalable and robust operators.
- Gelly features built-in algorithms, such as label propagation, triangle enumeration, and page rank, but provides also a Graph API that eases the implementation of custom graph algorithms.
Application Consistency & Recovery:
- Consistent Checkpoints: Flink’s recovery mechanism is based on consistent checkpoints of an application’s state. In case of a failure, the application is restarted and its state is loaded from the latest checkpoint. In combination with resettable stream sources, this feature can guarantee exactly-once state consistency.
- Efficient Checkpoints: Checkpointing the state of an application can be quite expensive if the application maintains terabytes of state. Flink’s can perform asynchronous and incremental checkpoints, in order to keep the impact of checkpoints on the application’s latency SLAs very small.
- High-Availability Setup: Flink feature a high-availability mode that eliminates all single-points-of-failure. The HA-mode is based on Apache ZooKeeper, a battle-proven service for reliable distributed coordination.
Savepoints to Migrate, Suspend, Resume and Update Application:
- A savepoint is a consistent snapshot of an application’s state and therefore very similar to a checkpoint. However in contrast to checkpoints, savepoints need to be manually triggered and are not automatically removed when an application is stopped.
- A savepoint can be used to start a state-compatible application and initialize its state. Savepoints enable the following features in Flink:
- Application Update: Savepoints can be used to update applications. A fixed or improved version of an application can be restarted from a savepoint that was taken from a previous version of the application. It is also possible to start the application from an earlier point in time (given such a savepoint exists) to repair incorrect results produced by the flawed version.
- Cluster Migration: Using savepoints, applications can be migrated (or cloned) to different clusters.
- Flink Version Updates: An application can be migrated to run on a new Flink version using a savepoint.
- Application Scaling: Savepoints can be used to increase or decrease the parallelism of an application.
- A/B Tests and What-If Scenarios: The performance or quality of two (or more) different versions of an application can be compared by starting all versions from the same savepoint.
- Pause and Resume: An application can be paused by taking a savepoint and stopping it. At any later point in time, the application can be resumed from the savepoint.
- Archiving: Savepoints can be archived to be able to reset the state of an application to an earlier point in time.
Monitoring & Control
- Flink integrates nicely with many common logging and monitoring services and provides a REST API to control applications and query information.
- Web UI: Flink features a web UI to inspect, monitor, and debug running applications. It can also be used to submit executions for execution or cancel them.
- Logging: Flink implements the popular slf4j logging interface and integrates with the logging frameworks log4j or logback.
- Metrics: Flink features a sophisticated metrics system to collect and report system and user-defined metrics. Metrics can be exported to several reporters, including JMX, Ganglia, Graphite, Prometheus, StatsD, Datadog, and Slf4j.
- REST API: Flink exposes a REST API to submit a new application, take a savepoint of a running application, or cancel an application. The REST API also exposes meta data and collected metrics of running or completed applications.
Flink Usecases:
Event-driven Applications
- Fraud detection
- Anomaly detection
- Rule-based alerting
- Business process monitoring
- Web application (social network)
Data Analytics Applications
- Quality monitoring of Telco networks
- Analysis of product updates & experiment evaluation in mobile applications
- Ad-hoc analysis of live data in consumer technology
- Large-scale graph analysis