Parallel Computing
- Uses multiple computer cores to attack several operations at once.
- Parallel Architecture breaks down a job into its component parts that can work in parallel, are mostly independent and multi-task them.
- These parts are allocated to different processors which execute them simultaneously.
- The first multi-core processors for Android and iPhone appeared in 2011 [1].
- IBM released the first multi-core processors for computers ten years before that in 2001 [2].
- Why???
- Exponential growth of processing and network speeds.
- Dual-core, quad-core, 8-core, and even 56-core chips are available[3].
- With Big data and the IoT adoptions, applications will soon be required to crunch trillions of data points at once. e.g., in healthcare sector, AI/ML tools will be rifling through the heart rates of a hundred million patients.
- Parallel Computing ways:
- Multithreading
- POSIX, C++11 Threads
- POSIX Threads of the same process can be scheduled and run on different processors/cores.
- POSIX, C++11 Threads
- Multiprocessing
- Multithreading
Multiprocessing Vs Parallel Processing
- Multiprocessing is the use of two or more central processing units (CPUs) within a single computer system. The term also refers to the ability of a system to support more than one processor and/or the ability to allocate tasks between them.
- parallel processing is the processing of program instructions by dividing them among multiple processors with the objective of running a program in less time with speed and efficiency.
Multiprocessing Vs Distributed Processing
- Multiprocessing works on the same physical machine/node with multiple processors/cores.
- Distributed Processing uses Multiprocessing, but Distributed processing needs to have the same program/processes running on multiple machines/nodes, connected over networks.
Concurrency Vs Parallelism
- Concurrency means that an application is making progress on more than one task at the same time (concurrently).
- Concurrency means executing multiple tasks at the same time but not necessarily simultaneously.
- Parallelism means that an application splits its tasks up into smaller subtasks which can be processed in parallel, for instance on multiple CPUs at the exact same time.
- In single-core CPU, you may get concurrency but NOT parallelism.
- A system is said to be concurrent if it can support two or more actions in progress at the same time.
- A system is said to be parallel if it can support two or more actions executing simultaneously.
- Concurrency and Parallelism are conceptually overlapped to some degree, but “in progress” clearly makes them different.
- Concurrency is about dealing with lots of things at once. Parallelism is about doing lots of things at once.
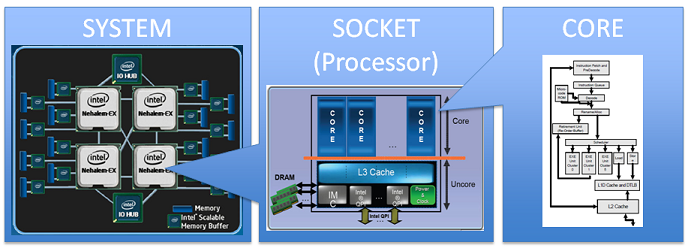
Cores Vs Processors & Hardware Threads
- A core is the most basic entity within a processor (CPU) that can completely handle execution of a program.
- CPU/Processor is an electronic circuit inside the computer that carries out instruction to perform arithmetic, logical, control and input/output operations
- While the core is an execution unit inside the CPU that receives and executes instructions.
Cores Vs Processors

An image may say more than a thousand words:
Hyperthreading or Simultaneous Multi-Threading (SMT)
- Hyperthreading - Intel
- Simultaneous Multi-Threading (SMT) - AMD
- Adding a second core to the CPU adds about 10% to the size and complexity, while doubling the performance.
- By adding hypertrheading to the mix you are improving that performance advantage to about 230%—all while using the same measly 15W of power.
- More cores and threads your CPU has, the more tasks it’s able to perform Concurrently & Simultaneously.
- Hyperthreading or Simultaneous Multi Threading (SMT) allows a core to store two processes at the same time, and operate on them separately. Each of these processes are stored in a hardware thread, also known as Hart or a thread.
- A CPU with 2 cores and 4 threads is a dual-core processor, which normally has only 2 threads but with hyperthreading/simultaneous multi-threading has 4 threads. So instead of being limited to running 2 instructions/tasks efficiently, it can run 4.
- A single complete “CPU” may be replicated onto a chip die, with each replication called a “core”. so a “CPU chip” with 2 such replications is said to have 2 cores. furthermore, each core has at least 1 “thread” = instruction stream (program), but it may have 2 or more threads. “2 cores and 4 threads” would usually mean each of the 2 CPU cores has 2 threads each. “threads” are the modern way of improving performance through parallel code execution (>=2 programs running concurrently).
Task Parallelism
- Also known as function parallelism and control parallelism
- It is a form of parallelization of computer code across multiple processors in parallel computing environments.
- Task parallelism focuses on distributing tasks—concurrently performed by processes or threads—across different processors.
- In contrast to Data parallelism which involves running the same task on different components of data,
- Task parallelism is distinguished by running many different tasks at the same time on the same data.
- A common type of task parallelism is pipelining which consists of moving a single set of data through a series of separate tasks where each task can execute independently of the others.
- In a multiprocessor system, task parallelism is achieved when each processor executes a different thread (or process) on the same or different data.
- The threads may execute the same or different code.
- In the general case, different execution threads communicate with one another as they work, but this is not a requirement. Communication usually takes place by passing data from one thread to the next as part of a workflow.
- Task parallelism emphasizes the distributed (parallelized) nature of the processing (i.e. threads), as opposed to the data (data parallelism).
- Language support:
- C++ (Intel): Threading Building Blocks
- C++ (Intel): Cilk Plus
- C++ (Open Source/Apache 2.0): RaftLib
- Go: goroutines
- Java: Java concurrency
- .NET: Task Parallel Library
Data Parallelism
- It focuses on distributing the data across different nodes, which operate on the data in parallel.
- It can be applied on regular data structures like arrays and matrices by working on each element in parallel.
- A data parallel job on an array of n elements can be divided equally among all the processors.
- Let us assume we want to sum all the elements of the given array and the time for a single addition operation is
Tatime units. In the case of sequential execution, the time taken by the process will ben×Tatime units as it sums up all the elements of an array. - On the other hand, if we execute this job as a data parallel job on 4 processors the time taken would reduce to
(n/4)×Ta + merging overheadtime units. - Parallel execution results in a speedup of 4 over sequential execution.
- Let us assume we want to sum all the elements of the given array and the time for a single addition operation is
- One important thing to note is that the locality of data references plays an important part in evaluating the performance of a data parallel programming model.
- Locality of data depends on the memory accesses performed by the program as well as the size of the cache.
- In a multiprocessor system, executing a single set of instructions (SIMD), data parallelism is achieved when each processor performs the same task on different distributed data.
- In some situations, a single execution thread controls operations on all the data. In others, different threads control the operation, but they execute the same code.
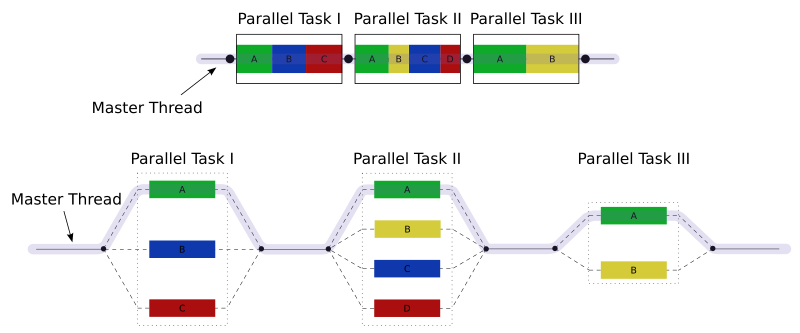
Fork-Join Model
- Parallel Computing Design Pattern
- A way of setting up and executing parallel programs, such that execution branches off in parallel at designated points in the program, to “join” (merge) at a subsequent point and resume sequential execution.
- Implementations of the fork–join model will typically fork tasks, fibers or lightweight threads, not operating-system-level “heavyweight” threads or processes.
- Fork–join is the main model of parallel execution in the OpenMP framework.
-
Also supported by the Java concurrency framework, and the Task Parallel Library for .NET.
-
Example:
mergesort(A, lo, hi):
if lo < hi: // at least one element of input
mid = ⌊lo + (hi - lo) / 2⌋
fork mergesort(A, lo, mid) // process (potentially) in parallel with main task
mergesort(A, mid, hi) // main task handles second recursion
join
merge(A, lo, mid, hi)
Map
- Map is an idiom in parallel computing where a simple operation is applied to all elements of a sequence, potentially in parallel.
- It is used to solve the problems that can be decomposed into independent subtasks, requiring no communication/synchronization between the subtasks except a join or barrier at the end.
- When applying the map pattern, one formulates an elemental function that captures the operation to be performed on a data item that represents a part of the problem, then applies this elemental function in one or more threads of execution, hyperthreads, SIMD lanes or on multiple computers.
- OpenMP has language support for the map pattern in the form of a parallel for loop.
- languages such as OpenCL and CUDA support elemental functions (as “kernels”) at the language level.
- The map pattern is typically combined with other parallel design patterns. For example, map combined with category reduction gives the MapReduce pattern.
Reduce
- The reduction operator is a type of operator that is commonly used in parallel programming to reduce the elements of an array into a single result.
- Reduction operators are associative and often (but not necessarily) commutative.
- The reduction of sets of elements is an integral part of programming models such as Map Reduce, where a reduction operator is applied (mapped) to all elements before they are reduced.
- Other parallel algorithms use reduction operators as primary operations to solve more complex problems.
- Many reduction operators can be used for broadcasting to distribute data to all processors.
MapReduce
- A programming model for processing and generating big data sets with a parallel, distributed algorithm on a cluster.
- A MapReduce program is composed of:
- a map procedure, which performs filtering and sorting.
- such as sorting students by first name into queues, one queue for each name.
- a reduce method, which performs a summary operation.
- such as counting the number of students in each queue, yielding name frequencies.
- a map procedure, which performs filtering and sorting.
- The “MapReduce System/framework” orchestrates the processing by marshalling the distributed servers, running the various tasks in parallel, managing all communications and data transfers between the various parts of the system, and providing for redundancy and fault tolerance.
- MapReduce specializes in the split-apply-combine strategy for data analysis.
- A popular open-source implementation of MapReduce that has support for distributed shuffles is part of Apache Hadoop.
Tools/APIs/Libraries for Parallel Processing
OpenMP
- OpenMP (Open Multi-Processing) are APIs that support multi-platform shared-memory multiprocessing programming in C, C++ on many platforms, instruction-set architectures and operating systems, including Solaris, AIX, FreeBSD, HP-UX, Linux, macOS, and Windows.
- It consists of a set of compiler directives, library routines, and environment variables that influence run-time behavior.
- Used for Parallel Processing applications for desktops and super-computers.
- OpenMP is used for parallelism within a (multi-core) node, while Message Passing Interface(MPI) is used for parallelism between nodes in a cluster.
Design
- OpenMP is an implementation of multithreading, a method of parallelizing whereby a primary thread (a series of instructions executed consecutively) forks a specified number of sub-threads and the system divides a task among them. The threads then run concurrently, with the runtime environment allocating threads to different processors.
- The section of code that is meant to run in parallel is marked accordingly, with a compiler directive that will cause the threads to form before the section is executed.
- Each thread has an id attached to it which can be obtained using a function (called omp_get_thread_num()).
- The thread id is an integer, and the primary thread has an id of 0.
- After the execution of the parallelized code, the threads join back into the primary thread, which continues onward to the end of the program.
- By default, each thread executes the parallelized section of code independently.
- Work-sharing constructs can be used to divide a task among the threads so that each thread executes its allocated part of the code.
- Both task parallelism and data parallelism can be achieved using OpenMP in this way.
- The runtime environment allocates threads to processors depending on usage, machine load and other factors. The runtime environment can assign the number of threads based on environment variables, or the code can do so using functions.
- The OpenMP functions are included in a header file labelled omp.h in C/C++.
Thread Creation
- pragma omp parallel is used to fork additional threads to carry out the work enclosed in the construct in parallel.
Work-sharing constructs
- Used to specify how to assign independent work to one or all of the threads.
- omp for or omp do: used to split up loop iterations among the threads, also called loop constructs.
- sections: assigning consecutive but independent code blocks to different threads
- single: specifying a code block that is executed by only one thread, a barrier is implied in the end
- master: similar to single, but the code block will be executed by the master thread only and no barrier implied in the end.
OpenCL
- OpenCL (Open Computing Language) is a framework for writing programs that execute across heterogeneous platforms consisting of central processing units (CPUs), graphics processing units (GPUs), digital signal processors (DSPs), field-programmable gate arrays (FPGAs) and other processors or hardware accelerators.
- OpenCL specifies programming languages (based on C99, C++14 and C++17) for programming these devices and application programming interfaces (APIs) to control the platform and execute programs on the compute devices.
- OpenCL provides a standard interface for parallel computing using task-parallelism and data-parallelism.
- Functions executed on an OpenCL device are called “kernels”.
- A single compute device typically consists of several compute units, which in turn comprise multiple processing elements (PEs). A single kernel execution can run on all or many of the PEs in parallel. How a compute device is subdivided into compute units and PEs is up to the vendor; a compute unit can be thought of as a “core”.
- OpenCL defines APIs that allows programs running on the host to launch kernels on the compute devices and manage device memory, which is (at least conceptually) separate from host memory.
- Programs in the OpenCL language are intended to be compiled at run-time, so that OpenCL-using applications are portable between implementations for various host devices.
- Languages supported:
- Primarily: C, C++
- with third-party: Python, Java, Perl, .Net
Pallelism in Python
Distributed Shared Memory (DSM)
- Distributed Shared Memory (DSM) is a form of memory architecture where physically separated memories can be addressed as one logically shared address space.
- “Shared” does not mean that there is a single centralized memory, but that the address space is "shared" (same physical address on two processors refers to the same location in memory).
- Distributed global address space (DGAS), is a similar term for a wide class of software and hardware implementations, in which each node of a cluster has access to shared memory in addition to each node's non-shared private memory.