- Pravega is a Distributed messaging systems such as Kafka and Pulsar which provide modern Pub/Sub infrastructure suitable for data-intensive applications.
- Pravega streams are durable, consistent, and elastic, while natively supporting long-term data retention.
- Pravega enhances the range of supported applications by efficiently handling both small events as in IoT and larger data as in videos for computer vision/video analytics.
- Pravega also enables replicating application state and storing key-value pairs.
Features
- Distributed Messaging System
- Supports messaging between processes (IPC like mechanism)
- Supports Leader Election, to select the master node in a cluster of machines.
- Pub/Sub infrastructure
- Streams
- Pravega Streams are Durable, meaning that Pravega creates 3 Replicas of a data, on 3 discs and it acknowledges the write-client only after it has written to all 3 dicsc. It’s NOT an in-memory replication, but on disc, and then acknowledgement.
- Consistent
- Elastic
- Append-only
- Event Streams
- Event is delivered & processed Exactly Once. Every event gets an ID and an Acknowledgement is sent back to client. Same event sent by client is rejected by Pravega system.
- Long term data retention
- Pravega provides Data Storage mechanism, that Retain data streams forever.
- Data storage supports Real-time & Historical Data use-cases
- Pravega supports both File or Object store
- HDFS
- NFS
- Dell ECS S3
- Data Types variations
- Supports IoT Data handling (Small Events)
- Also, Video/Audio (Large Data)
- Replication of Application State, State Synchronizer
- Used for coordinating processes in a distributed computing environment.
- Uses a Pravega Stream to provide a synchronization mechanism for state shared between multiple processes running in a cluster.
- Used to maintain a single, shared copy of an application's configuration property across all instances.
- Storing Key-Value Pairs
- Auto Scaling
- Supported for every Individual data Streams, As per data ingestion rate
- Multi-tenancy supported
- Supports High Partitions count
- Fault Tolerant
- Provega guarantees events Ordering, even in-case of client/server/network failure.
- Milliseconds of Write frequency is supported by Pravega, which is ideal and many time a requirement for IoT sensors streams & Time Sensitive Applications.
- 1000s of clients Read/Write supported.
- Pravega sents a Write acknowledgement to clients, only after data is stored/persisted & protected.
- Tiered Storage
- Tier-1 storage is write efficient storage, data is ingested first here. It’s a Log Data Structure implemented with Open-source Apache BookKeeper Project. Tier-1 storage is typically implemented on: faster SSDs, non-volatile RAM.
- Log Data Structure: Log is the simplest data structure that represents append-only sequence of records. Log records are immutable and appended in strictly sequential order to the end of the log file.
- Log is a fundamental data structure used for write-intensive applications.
- Tier-2 storage is throughput efficient, uses spinning discs. It’s implemented with HDFS model.
- Pravega asynchronously migrates Events from Tier-1 to Tier-2 to reflect the different access patterns to Stream data.
- Tier-1 storage is write efficient storage, data is ingested first here. It’s a Log Data Structure implemented with Open-source Apache BookKeeper Project. Tier-1 storage is typically implemented on: faster SSDs, non-volatile RAM.
- Data Pipelines
- Real-time for data processing
- Batching processing
- Transactions
- With Pravega Transactions, either Complete Data is written to streams, Or Complete Data is trashed, and the transaction is aborted.
- Useful when a Writer can “batch” up a bunch of Events and commit them as a unit into a Stream.
- Transactions need to be created explicitly, when writing events.
- Transaction Segments:
- Transactions have their own segments exactly similar (one-to-one matching) to Stream segments.
- Events are first published to Transaction segments and the writer-client is acknowledged.
- On commit, all of the Transaction Segments are written to Stream Segments.
- Events published into a Transaction are visible to the Reader only after the Transaction is committed.
- On error, all Transaction segments and events in them are discarded.
Pravega Events
- In Pravega, Data being Written/Read to Streams are all Events.
- Java Serializer, deserializer is used to make sense/parse of events.
- Routing Key
- Used to group similar events, e.g., consumer-id, machine-id, sensor-id
- Routing Keys are important in defining the read and write semantics that Pravega guarantees.
- When an Event is written into a Stream, it is stored in one of the Stream Segments based on the Event's Routing Key.
- Segments consists of a range of routing keys, e.g., like Postal ZIP codes for various orders.
- Routing Keys are hashed to form a "key space".
- Ordering Guarantee
- Events with the same Routing Key are consumed in the order they were written.
- If an Event has been acknowledged to its Writer or has been read by a Reader, it is guaranteed that it will continue to exist in the same location or position for all subsequent reads until it is deleted.
Pravega Streams
- Scaling
- Streams are NOT Statically Partitioned.
- Streams are <>Unbounded</u>, i.e., No limit on number of events/bytes/size.
- Segments
- Every stream is made of segments.
- Number of segments in a stream varies over a lifetime of the stream.
- Number of segments in a stream depends upon volume of data ingestion.
- Segments of the same stream can be placed on different machines/nodes, Horizontal Scaling.
- Segments can be merged back when volume of data is low.
- Stream Segments are configurable.
- An Event written to a Stream is written to any single Stream Segment.
- Segment Store Service
- It buffers the incoming data in a very fast and durable append-only medium (Tier-1)
- It syncs the data to a high-throughput (but not necessarily low latency) system (Tier-2) in the background.
- It supports arbitrary-offset reads.
- Stream Segments are unlimited in length.
- Supports Multiple concurrent writers to the same Stream Segment.
- Order is guaranteed within the context of a single Writer.
- Appends from multiple concurrent Writers will be added in the order in which they were received.
- It supports Writing to and reading from a Stream Segment concurrently.
- Scaling Policies:
- Scaling Policies can be configured in following 3 types:
- Fixed:
- The number of Stream Segments does not vary with load.
- Data-based:
- It splits a Stream Segment into multiple ones (i.e., Scale-up Event) if the number of bytes per second written to that Stream Segment increases beyond a defined threshold.
- Similarly, Pravega merges two adjacent Stream Segments (i.e., Scale-down Event) if the number of bytes written to them fall below a defined threshold.
- Note that, even if the load for a Stream Segment reaches the defined threshold. Pravega does not immediately trigger a Scale-up/down Event. Instead, the load should be satisfying the scaling policy threshold for a sufficient amount of time.
- Event-based:
- Uses number of events instead of bytes as threashold, otherwise it’s similar to Data-based policy.
- Append-only Log data structure
- With this, Pravega only supports write to front (~tail).
- But, Read from any point, developers have control over the Reader’s start position in the Stream.
- Supports Read/Write in parallel.
- Stream Scopes
- Pravega supports Stream organization, equivalent to Namespaces.
- Stream Name MUST be Unique within a Scope.
- It is used to classify streams by tenants, departments, geo locations.
Deployment
- Pravega Deployment Overview
- Deployment modes:
- Standalone
- Distributed
- Local/testing Deployment
- Production Deployment
- Deployment modes:
- Configuration and Provisioning Guide for production clusters.
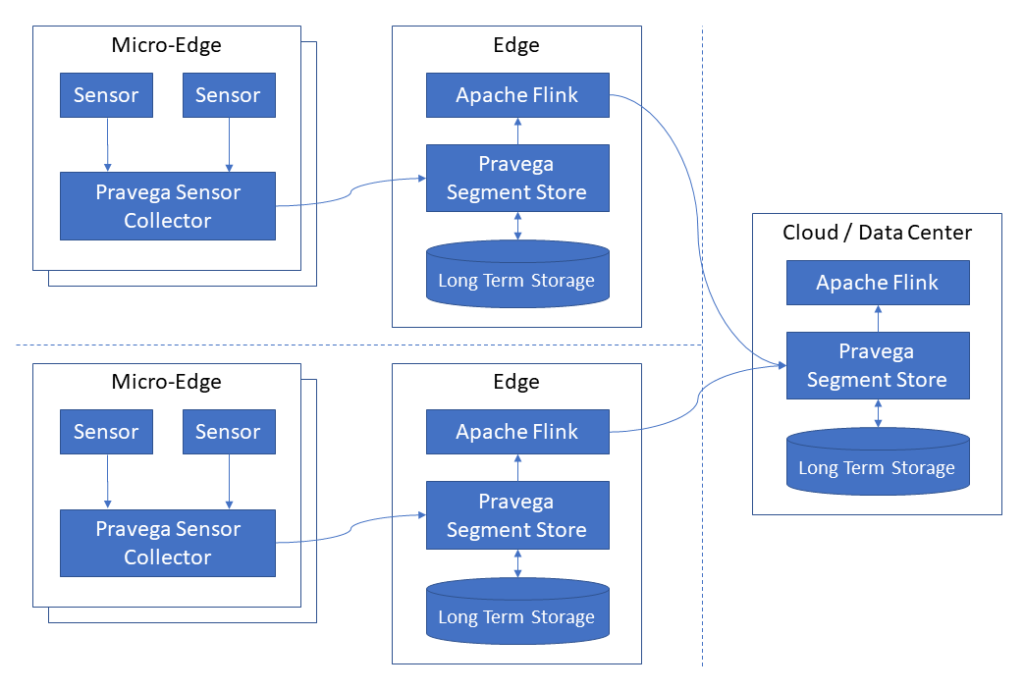
Pravega Data Flow Solution Overview
Apache Flink connectors for Pravega
-
The Flink Connector enables building end-to-end stream processing pipelines with Pravega in Apache Flink. This also allows reading and writing data to external data sources and sinks via Flink Connector.
- Introduction to Pravega Flink Connector:
- Apache Flink connectors for Pravega
- Flink Connector Examples for Pravega
- Pravega Flink Tools
Usecase: Real-Time Object Detection with Pravega and Flink
Apache Spark Connector:
- Connector to read and write Pravega Streams with Apache Spark, a high-performance analytics engine for batch and streaming data.
- The connector can be used to build end-to-end stream processing pipelines that use Pravega as the stream storage and message bus, and Apache Spark for computation over the streams.
- Spark Connector
Hadoop Connector:
- Implements both the input and the output format interfaces for Apache Hadoop.
- It leverages Pravega batch client to read existing events in parallel; and uses write API to write events to Pravega streams.
- Hadoop Connector
Presto Connector:
- Presto is a distributed SQL query engine for big data.
- Presto uses connectors to query storage from different storage sources. This connector allows Presto to query storage from Pravega streams.
- Presto Connector
Pravega: Rethinking Storage for Streams
Dell Streaming Data Platform (SDP)
- An Enterprise solution to address a wide range of use cases to reunite the Operational Technology (OT) world and the IT world with following key features:
- Ingestion of data
- IoT sensor data
- Video data
- log files
- High Frequency Data
- Data Collection
- at the edge or
- at the core data center.
- Analyze data
- in real-time
- in batch
- generate alert based on that specific data set.
- Data Sync
- Synchronize data from the edge to the core data center
- for analysis or ML model development (training).
- Ingestion of data
Pravega Usage in SDP
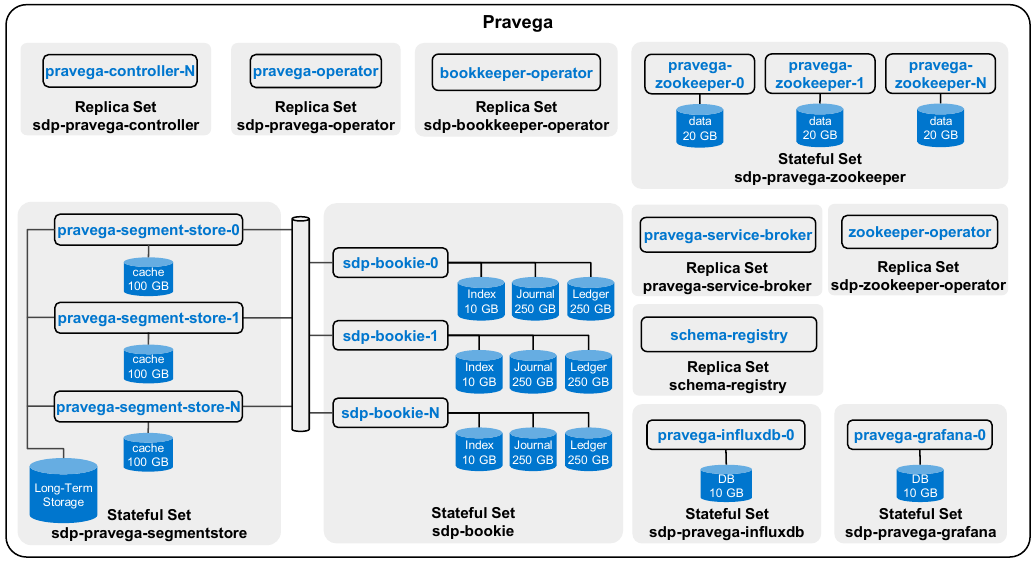
Complete Dell SDP Architecture:
SDP Code Hub
- An essential collection of Code sample, Demos, and Connectors To kisck-start your projects on the DELL EMC Streaming Data Platform.
- SDP Code Hub: Sample Code
- SDP Code Hub: Connectors
- SDP Code Hub: Demos
- StreamingDataPlatform/code-hub