This write-up will only focus on AWS Sagemaker ML service with respect to ML model deployment to Edge devices and Cloud.
AWS Sagemaker Neo
- Amazon SageMaker Neo enables developers to optimize machine learning (ML) models for inference on SageMaker on the cloud and supported devices at the edge for the specific underlying hardware.
- Optimizes machine learning models for inference on cloud instances and edge devices to run faster with no loss in accuracy.
- Amazon SageMaker Neo runtime is supported on Android, iOS, Linux, and Windows operating systems.
- Sagemaker neo can optimize the ML model to run on target hardware platform of Edge devices based on processors from Ambarella, Apple, ARM, Intel, MediaTek, Nvidia, NXP, Qualcomm, RockChip, Texas Instruments, or Xilinx.
- Compiles it into an executable.
- For inference in the cloud, SageMaker Neo speeds up inference and saves cost by creating an inference optimized container that include MXNet, PyTorch, and TensorFlow integrated with Neo runtime for SageMaker hosting.
- Amazon SageMaker Neo supports optimization for a model from the framework-specific format of DarkNet, Keras, MXNet, PyTorch, TensorFlow, TensorFlow-Lite, ONNX, or XGBoost.
- Amazon SageMaker Neo runtime occupies 1MB of storage and 2MB of memory, which is many times smaller than the storage and memory footprint of a framework, while providing a simple common API to run a compiled model originating in any framework.
- Amazon SageMaker Neo takes advantage of partner-provided accelerator libraries to deliver the best available performance for a deep learning model on heterogeneous hardware platforms with a hardware accelerator as well as a CPU. Acceleration libraries such as Ambarella CV Tools, Nvidia Tensor RT, and Texas Instruments TIDL each support a specific set of functions and operators. SageMaker Neo automatically partitions your model so that the part with operators supported by the accelerator can run on the accelerator while the rest of the model runs on the CPU.
- Amazon SageMaker Neo now compiles models for Amazon SageMaker INF1 instance targets. SageMaker hosting provides a managed service for inference on the INF1 instances, which are based on the AWS Inferentia chip.
AWS Sagemaker Edge Manager
- AWS Sagemaker Edge Manager consists of a Service running in AWS cloud and an Agent running on Edge devices.
- Sagemaker Edge Manager deploys a ML model optimized with SageMaker Neo automatically so you don’t need to have Neo runtime installed on your devices in order to take advantage of the model optimizations.
Agent
- Use the agent to make predictions with models loaded onto your edge devices.
- The agent also collects model metrics and captures data at specific intervals.
- Sample data is stored in your Amazon S3 bucket.
- 2 methods of installing and deploying the Edge Manager agent onto your edge devices:
- Download the agent as a binary from the Amazon S3 release bucket.
- Deploy aws.greengrass.SageMakerEdgeManager to __AWS IoT Greengrass V2
- Use AWS Greengrass v2 Console
- or Use AWS CLI
Monitoring deployments across fleets
- SageMaker Edge Manager also collects prediction data and sends a sample of the data to the cloud for monitoring, labeling, and retraining.
- All data can be viewed in the SageMaker Edge Manager dashboard which reports on the operation of deployed models.
- The dashboard is useful to understand the performance of models running on each device across your fleet, understand overall fleet health and identify problematic models and particular devices.
- If quality declines are detected, you can quickly spot them in the dashboard and also configure alerts through Amazon CloudWatch.
Signed and Verifiable ML deployments
- SageMaker Edge Manager also cryptographically signs your models so you can verify that it was not tampered with as it moves from the cloud to edge devices.
Integration with device applications
- SageMaker Edge Manager supports gRPC, an open source remote procedure call, which allows you to integrate SageMaker Edge Manager with your existing edge applications through APIs in common programming languages, such as Android Java, C# / .NET, Dart, Go, Java, Kotlin/JVM, Node.js, Objective-C, PHP, Python, Ruby, and Web.
- Manages models separately from the rest of the application, so that updates to the model and the application are independent.
Multiple ML models serve on edge devices [upcoming feature]
- ML applications usually require hosting and running multiple models concurrently on a device.
- SageMaker Edge Manager will soon allow you to write simple application logic to send one or more queries (i.e. load/unload models, run inference) independently to multiple models and rebalance hardware resource utilization when you add or update a model.
Model Registry and Lifecycle [upcoming feature]
- SageMaker Edge Manager will soon be able to automate the build-train-deploy workflow from cloud to edge devices in Amazon SageMaker Edge Manager, and trace the lifecycle of each model.
AWS Outpost and AWS Sagemaker Edge Manager
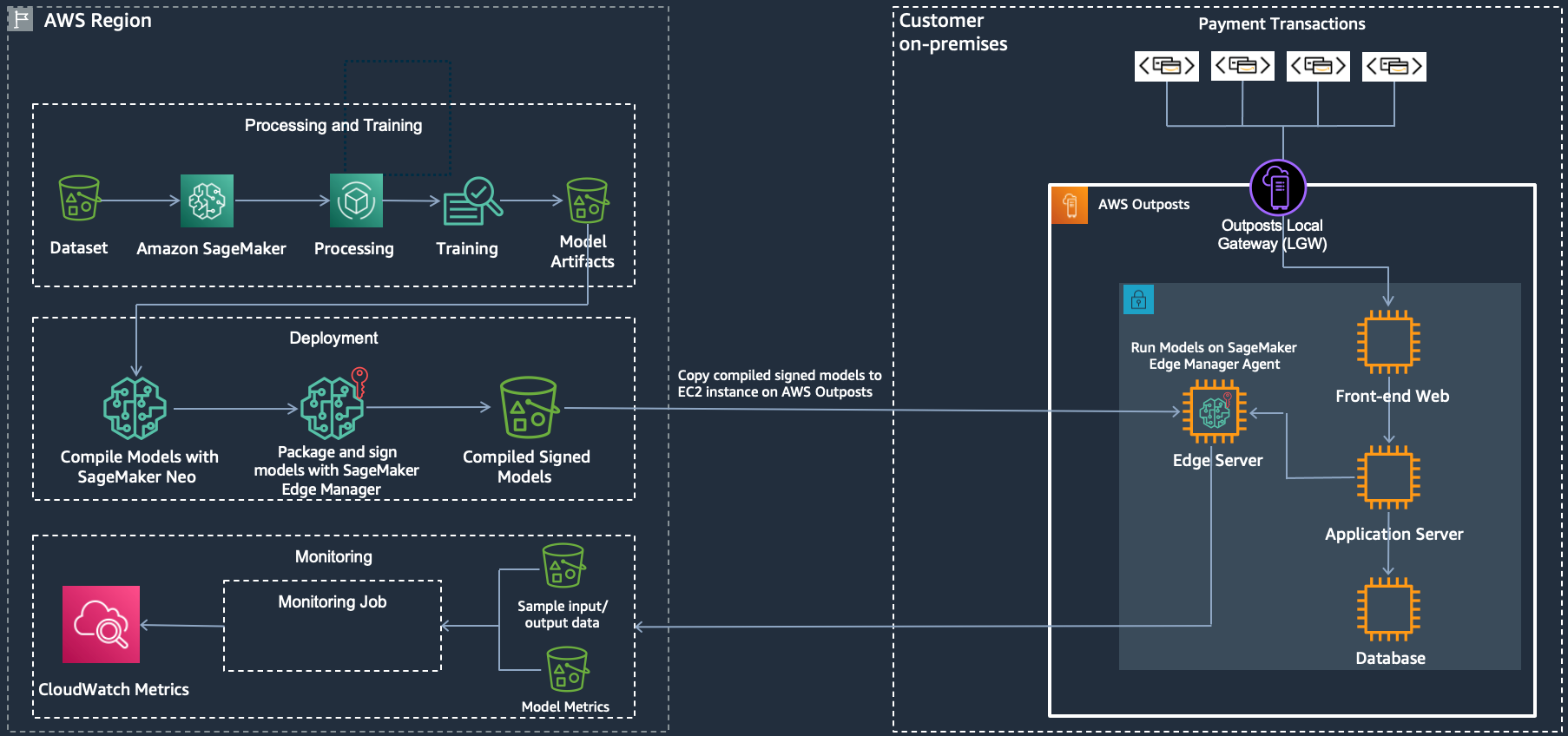
Further References:
- Amazon SageMaker Neo makes it easier to get faster inference for more ML models with NVIDIA TensorRT